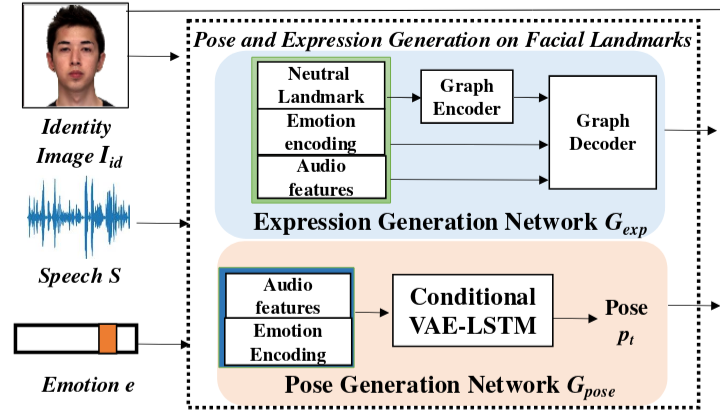
Generating realistic one-shot emotional talking head animation on arbitrary faces is a challenging problem, as it requires realistic emotions, head movements, identity preser vation, and accurate lip sync. Existing emotional talking face generation methods either fail to retain the identity information of arbitrary subjects owing to the limited variability of existing emotional datasets, or they fail to capture emotions accurately even if they preserve identity of arbitrary faces. Moreover, most of the methods rely on additional input videos for driving poses and/or or expressions
on the generated video. For practical applications, it is in feasible to obtain driving videos of the same or different subject with variations in head pose, expressions etc. In this paper, we propose a novel approach for Audio-driven Emotional Talking Head generation from a single image, with emotion-controllable head pose generation. Unlike existing
methods, our method does not require a driving video either for pose or emotions, and can generate different emotions and diverse head pose variations from input speech and a single image of an arbitrary subject in neutral emotion. Our method overcomes the limitations of existing emotional audio-visual datasets by learning a disentangled approach for optical flow computation approach for pose and expression. Using our proposed method of independently computing pose-driven and expression-driven optical flow,
our image generation network can be pre-trained on a large dataset with greater pose variability but lacking emotion annotations. The expression flow generation branch is fine tuned on a smaller emotional dataset to accurately capture
different emotions not present in the original dataset, while retaining the pose variability from the original dataset. We present extensive experiments to demonstrate the superior ity of our proposed method in generating talking head animation with accurate emotions, diverse head movements, and generalization to arbitrary faces.
@inproceedings{Sinha_2025_WACV,title={DisFlowEm : One-Shot Emotional Talking Head Generation using Disentangled Pose and Expression Flow-Guidance},author={Sinha, Sanjana and Bhowmick, Brojeshwar and Tiwari, Lokender and Chanda, Sushovan},booktitle={ Proceedings of the Winter Conference on Applications of Computer Vision (WACV)},year={2025},}
2023
Enhanced Spatio-Temporal Context for Temporally Consistent Robust 3D Human Motion Recovery from Monocular Videos
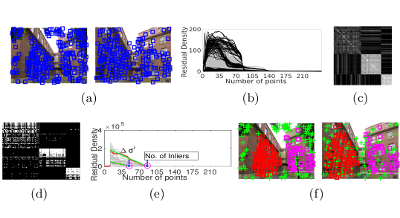
Recovering temporally consistent 3D human body pose, shape and motion from a monocular video is a challenging task due to (self-)occlusions, poor lighting conditions, complex articulated body poses, depth ambiguity, and limited availability of annotated data. Further, doing a simple perframe estimation is insufficient as it leads to jittery and implausible results. In this paper, we propose a novel method for temporally consistent motion estimation from a monocular video. Instead of using generic ResNet-like features, our method uses a body-aware feature representation and an independent per-frame pose and camera initialization over a temporal window followed by a novel spatio-temporal feature aggregation by using a combination of self-similarity and self-attention over the body-aware features and the perframe initialization. Together, they yield enhanced spatiotemporal context for every frame by considering remaining past and future frames. These features are used to predict the pose and shape parameters of the human body model, which are further refined using an LSTM. Experimental results on the publicly available benchmark data show that our method attains significantly lower acceleration error and outperforms the existing state-of-the-art methods over all key quantitative evaluation metrics, including complex scenarios like partial occlusion, complex poses and even relatively low illumination.
@inproceedings{chanda2023enhanced,title={Enhanced Spatio-Temporal Context for Temporally Consistent Robust 3D Human Motion Recovery from Monocular Videos},author={Chanda, Sushovan and Tiwari, Amogh and Tiwari, Lokender and Bhowmick, Brojeshwar and Sharma, Avinash and Barua, Hrishav},booktitle={ arXiv preprint arXiv:2311.11662 },year={2023},}
In this paper, we propose a novel generic garment simulator to drape a template 3D garment of arbitrary type, size, and topology onto an arbitrary 3D body shape and pose. Existing learning-based methods for 3D garment simulation methods train a single model for each garment type, with a fixed topology. Most of them use supervised learning, which requires huge training data that is expensive
to acquire. Our method circumvents the above-mentioned limitations by proposing GenSim, a generic unsupervised method for garment simulation, that can generalize to garments of different sizes, topologies, body shapes, and poses, using a single trained model. Our proposed GenSim consists of (1) a novel body-motion-aware as-rigid-as-possible (ARAP) garment deformation module that initially deforms
the template garment considering the underlying body as an obstacle and (2) a Physics Enforcing Network (PEN) that adds the corrections to the ARAP deformed garment to make it physically plausible. PEN uses multiple types of garments of arbitrary topology for training using physicsaware unsupervised losses. Experimental results show that our method significantly outperforms the existing state-ofthe-art methods on the challenging CLOTH3D [4] dataset and the VTO [23] dataset. Unlike the unsupervised method PBNS [5], GenSim generalizes well on unseen garments with varying shapes, sizes, types, and topologies draped on different body shapes and poses.
@inproceedings{tiwari2023gensim,title={GenSim: Unsupervised Generic Garment Simulator (<b>ORAL</b>)},author={Tiwari, Lokender and Bhowmick, Brojeshwar and Sinha, Sanjana},booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (<b>CVPR</b>), Deep Learning for Geometric Computing Workshop },pages={4168--4177},year={2023},demo={https://drive.google.com/file/d/1nZuJlsQN2OqVXBobNNn336UK8dXNc3nC/view?usp=sharing},}
We present a particle-based neural garment simulator (dubbed as GarSim) that can simulate template garments on the target arbitrary body poses. Existing learning-based methods majorly work for specific garment type (e.g. t-shirt, skirt, etc) or garment topology, and needs retraining for a new type of garment. Similarly, some methods focus on a particular fabric, body shape, and pose. To circumvent these limitations, our method fundamentally learns the physical dynamics of the garment vertices conditioned on underlying body shape, motion, and fabric properties to generalize across garment types, topology, and fabric along with different body shape and pose. In particular, we represent the garment as a graph, where the nodes represent the physical state of the garment vertices, and the edges represent the relation between the two nodes. The nodes and edges of the garment graph encode various properties of garments and the human body to compute the dynamics of the vertices through a learned message-passing. Learning of such dynamics of the garment vertices conditioned on underlying body motion and fabric properties enables our method to be trained simultaneously for multiple types of garments (e.g., tops, skirts, etc) with arbitrary mesh resolutions, varying topologies, and fabric properties. Our experimental results show that GarSim with less amount of training data not only outperforms the SOTA methods on challenging CLOTH3D dataset both qualitatively and quantitatively, but also works reliably well on the unseen poses obtained from YouTube videos, and give satisfactory results on unseen cloth types which were not present during the training.
@inproceedings{tiwari2023garsim,title={GarSim: Particle Based Neural Garment Simulator},author={Tiwari, Lokender and Bhowmick, Brojeshwar},booktitle={IEEE/CVF Winter Conference on Applications of Computer Vision (<b>WACV</b>)},pages={4472--4481},year={2023},}
2022
A Review on Monocular Tracking and Mapping: From Model-Based to Data-Driven Methods
Nivesh Gadipudi, Irraivan Elamvazuthi, Lila Iznita Izhar, Lokender Tiwari, and
3 more authors
The Visual Computer, International Journal of Computer Graphics, 2022
Visual odometry and visual simultaneous localization and mapping aid in tracking the position of a camera and mapping the surroundings using images. It is an important part of robotic perception. Tracking and mapping using a monocular camera is cost-effective, requires less calibration effort, and is easy to deploy across a wide range of applications. This paper provides an extensive review of the developments for the first two decades of the twenty-first century. Astounding results from early methods based on filtering have intrigued the community to extend these algorithms using other forms of techniques like bundle adjustment and deep learning. This article starts by introducing the basic sensor systems and analyzing the evolution of monocular tracking and mapping algorithms through bibliometric data. Then, it covers the overview of filtering and bundle adjustment methods, followed by recent advancements in methods using deep learning with the mathematical constraints applied on the networks. Finally, the popular benchmarks available for developing and evaluating these algorithms are presented along with a comparative study on a different class of algorithms. It is anticipated that this article will serve as the latest introductory tool and further ignite the interest of the community to solve current and future impediments.
@article{gadipudi2022review,title={A Review on Monocular Tracking and Mapping: From Model-Based to Data-Driven Methods},author={Gadipudi, Nivesh and Elamvazuthi, Irraivan and Izhar, Lila Iznita and Tiwari, Lokender and Hebbalaguppe, Ramya and Lu, Cheng-Kai and Doss, Arockia Selvakumar Arockia},journal={The Visual Computer, International Journal of Computer Graphics},pages={1--28},year={2022},publisher={Springer},}
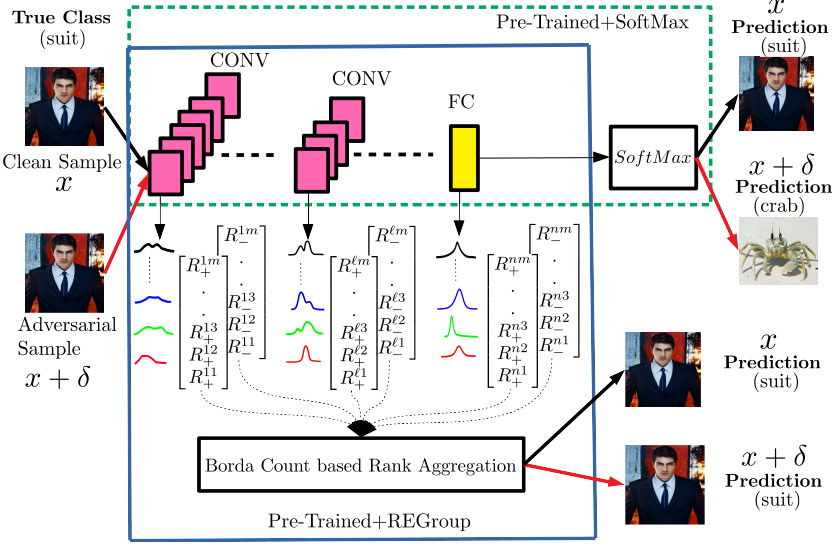
REGroup: Rank-aggregating Ensemble of Generative Classifiers for Robust Predictions
Lokender Tiwari, Anish Madan, Saket Anand, and Subhashis Banerjee
In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022
Deep Neural Networks (DNNs) are often criticized for being susceptible to adversarial attacks. Most successful defense strategies adopt adversarial training or random input transformations that typically require retraining or fine-tuning the model to achieve reasonable performance. In this work, our investigations of intermediate representations of a pre-trained DNN lead to an interesting discovery pointing to intrinsic robustness to adversarial attacks. We find that we can learn a generative classifier by statistically characterizing the neural response of an intermediate layer to clean training samples. The predictions of multiple such intermediate-layer based classifiers, when aggregated, show unexpected robustness to adversarial attacks. Specifically, we devise an ensemble of these generative classifiers that rank-aggregates their predictions via a Borda count-based consensus. Our proposed approach uses a subset of the clean training data and a pre-trained model, and yet is agnostic to network architectures or the adversarial attack generation method. We show extensive experiments to establish that our defense strategy achieves state-of-the-art performance on the ImageNet validation set.
@inproceedings{tiwari2022regroup,title={REGroup: Rank-aggregating Ensemble of Generative Classifiers for Robust Predictions},author={Tiwari, Lokender and Madan, Anish and Anand, Saket and Banerjee, Subhashis},journal={WACV, 2023},booktitle={IEEE/CVF Winter Conference on Applications of Computer Vision (<b>WACV</b>)},pages={2595--2604},year={2022},}
2021
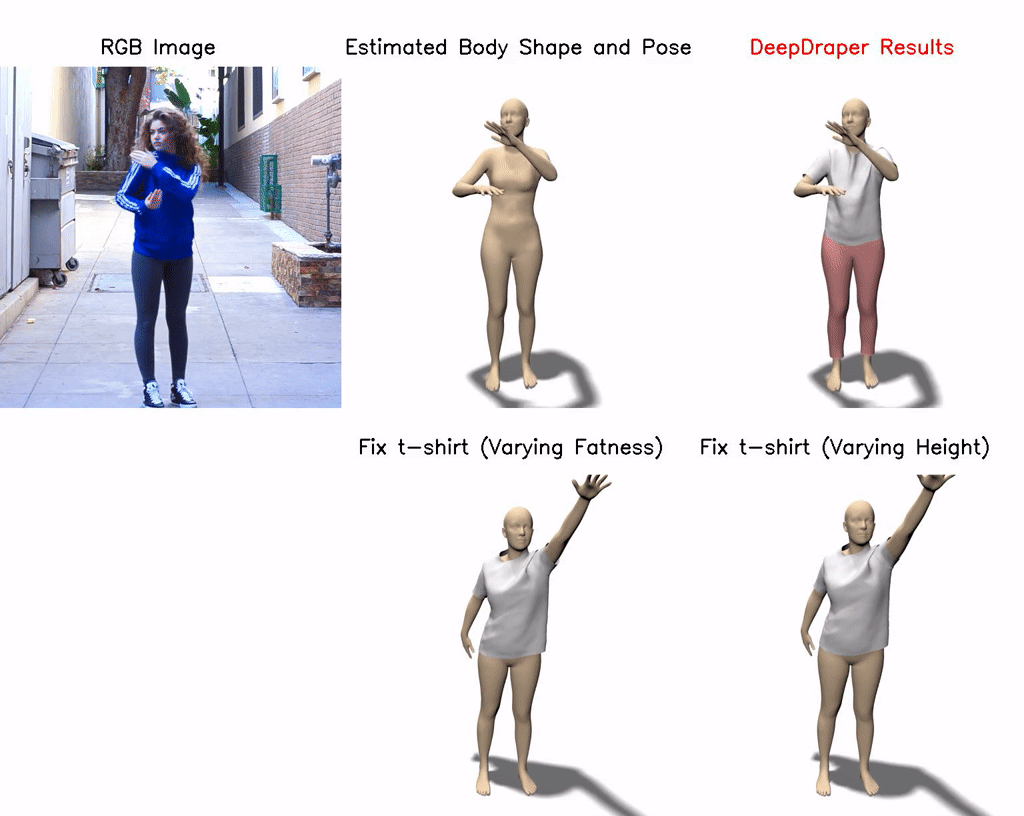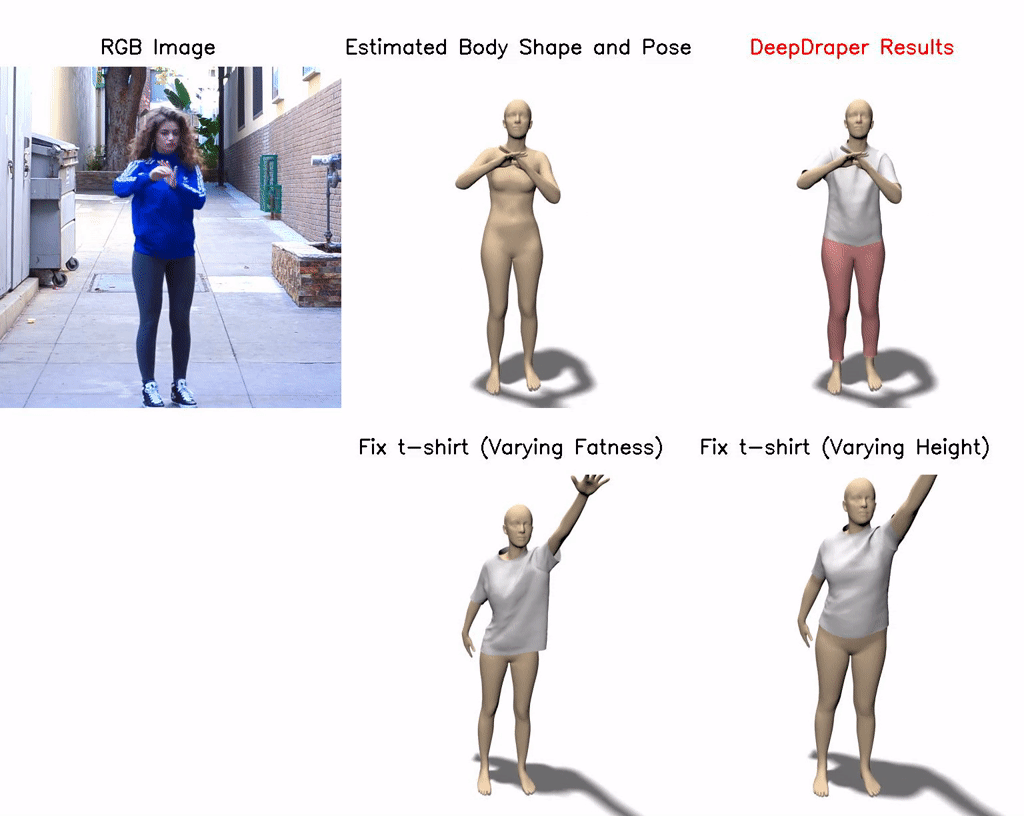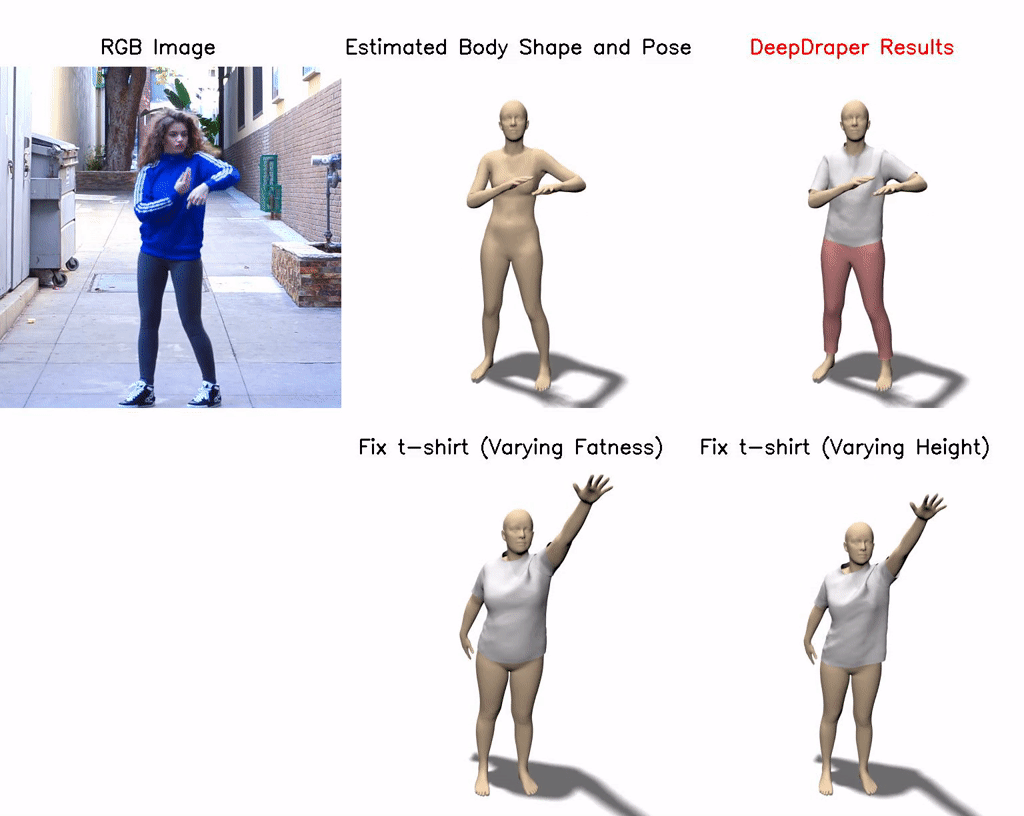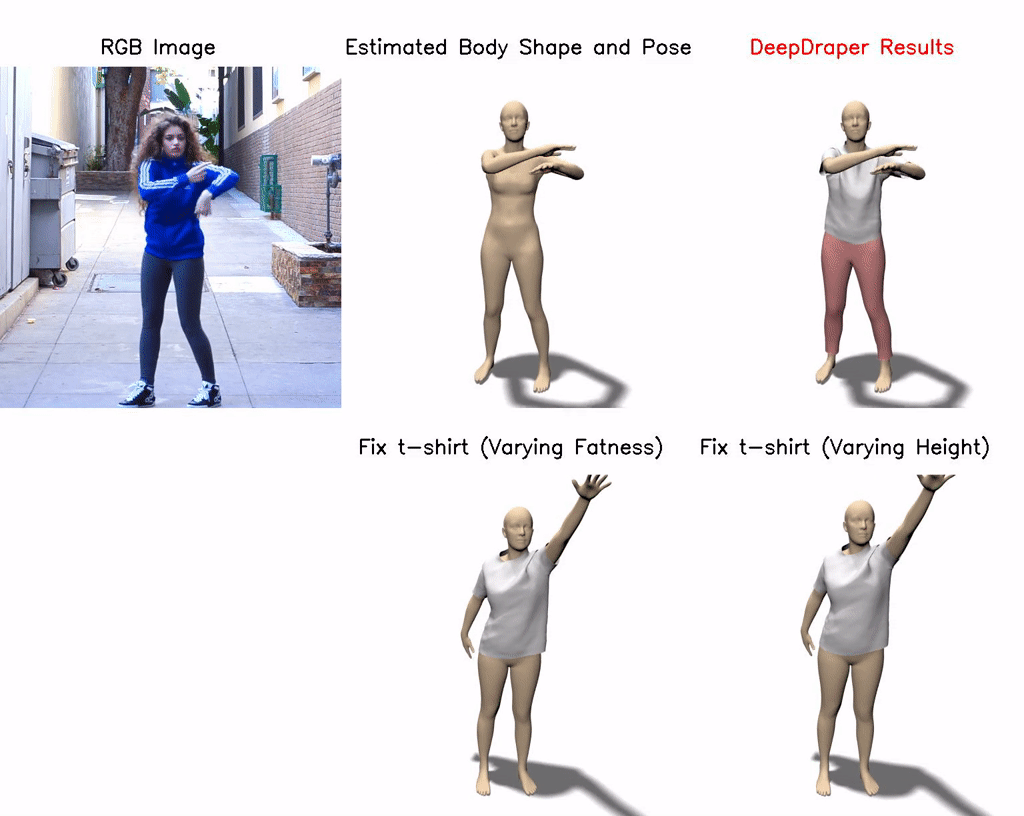
DeepDraper: Fast and Accurate 3D Garment Draping over a 3D Human Body
Draping a 3D human mesh has garnered broad interest due to its wide applicability in virtual try-on, animations, etc. The 3D garment deformations produced by the existing methods are often inconsistent with the body shape, pose, and measurements. This paper proposes a single unified learning-based framework (DeepDraper) to predict garment deformation as a function of body shape, pose, measurements, and garment styles. We train the DeepDraper with coupled geometric and multi-view perceptual losses. Unlike existing methods, we additionally model garment deformations as a function of standard body measurements, which generally a buyer or a designer uses to buy or design perfect fit clothes. As a result, DeepDraper significantly outperforms the state-of-the-art deep network-based approaches in terms of fitness and realism and generalizes well to the unseen style of the garments. In addition to that, DeepDraper is 10 times smaller in size and 23 times faster than the closest state-of-the-art method (TailorNet), which favors its use in real-time applications with less computational power. Despite being trained on the static poses of the TailorNet dataset, DeepDraper generalizes well to unseen body shapes, poses, and garment styles and produces temporally coherent garment deformations on the pose sequences even from the unseen AMASS dataset.
@inproceedings{tiwari2021deepdraper,title={DeepDraper: Fast and Accurate 3D Garment Draping over a 3D Human Body},author={Tiwari, Lokender and Bhowmick, Brojeshwar},booktitle={IEEE/CVF International Conference on Computer Vision (<b>ICCV</b>), Differentiable 3D Vision and Graphics Workshop },pages={1416--1426},year={2021},}
2020
Pseudo RGB-D for Self-Improving Monocular SLAM and Depth Prediction
Lokender Tiwari, Pan Ji, Quoc-Huy Tran, Bingbing Zhuang, and
2 more authors
In European conference on computer vision (ECCV), 2020
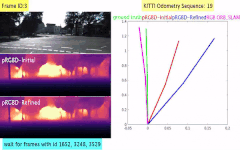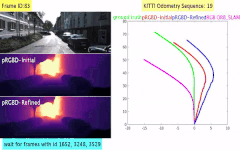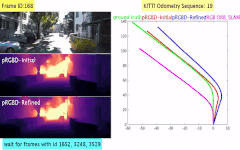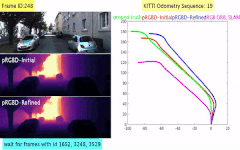
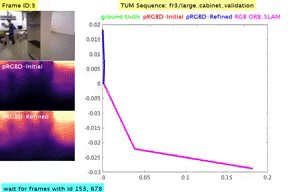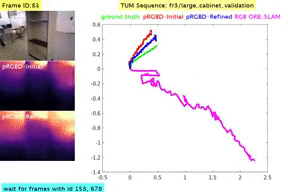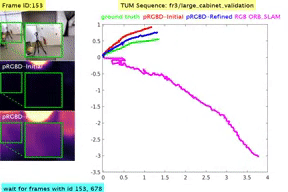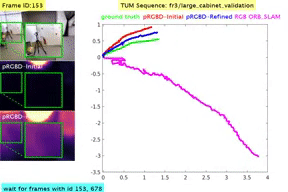
Classical monocular Simultaneous Localization And Mapping (SLAM) and the recently emerging convolutional neural networks (CNNs) for monocular depth prediction represent two largely disjoint approaches towards building a 3D map of the surrounding environment. In this paper, we demonstrate that the coupling of these two by leveraging the strengths of each mitigates the other’s shortcomings. Specifically, we propose a joint narrow and wide baseline based self-improving framework, where on the one hand the CNN-predicted depth is leveraged to perform pseudo RGB-D feature-based SLAM, leading to better accuracy and robustness than the monocular RGB SLAM baseline. On the other hand, the bundle-adjusted 3D scene structures and camera poses from the more principled geometric SLAM are injected back into the depth network through novel wide baseline losses proposed for improving the depth prediction network, which then continues to contribute towards better pose and 3D structure estimation in the next iteration. We emphasize that our framework only requires unlabeled monocular videos in both training and inference stages, and yet is able to outperform state-of-the-art self-supervised monocular and stereo depth prediction networks (e.g., Monodepth2) and feature-based monocular SLAM system (i.e., ORB-SLAM). Extensive experiments on KITTI and TUM RGB-D datasets verify the superiority of our self-improving geometry-CNN framework.
@inproceedings{tiwari2020pseudo,title={Pseudo RGB-D for Self-Improving Monocular SLAM and Depth Prediction},author={Tiwari, Lokender and Ji, Pan and Tran, Quoc-Huy and Zhuang, Bingbing and Anand, Saket and Chandraker, Manmohan},booktitle={European conference on computer vision (<b>ECCV</b>)},pages={437--455},year={2020},organization={Springer},}
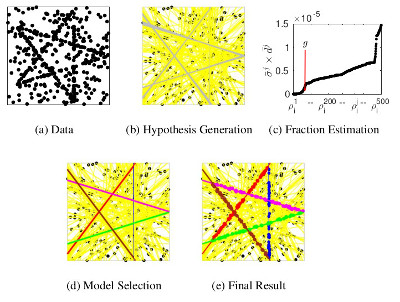
In this paper, we present an automatic multi-model fitting pipeline that can robustly fit multiple geometric models present in the corrupted and noisy data. Our approach can handle large data corruption and requires no user input, unlike most state-of-the-art approaches. The pipeline can be used as an independent block in many geometric vision applications like 3D reconstruction, motion and planar segmentation. We use residual density as the primary tool to guide hypothesis generation, estimate the fraction of inliers, and perform model selection. We show results for a diverse set of geometric models like planar homographies, fundamental matrices and vanishing points, which often arise in various computer vision applications. Despite being fully automatic, our approach achieves competitive performance compared to state-of-the-art approaches in terms of accuracy and computational time.
@inproceedings{tiwari2018dgsac,title={DGSAC: Density Guided Sampling and Consensus},author={Tiwari, Lokender and Anand, Saket},booktitle={IEEE Winter Conference on Applications of Computer Vision ((<b>WACV</b>)},pages={974--982},year={2018},organization={IEEE},}
2017
Robust Multi-Model Fitting using Density and Preference Analysis
Robust multi-model fitting problems are often solved using consensus based or preference based methods, each of which captures largely independent information from the data. However, most existing techniques still adhere to either of these approaches. In this paper, we bring these two paradigms together and present a novel robust method for discovering multiple structures from noisy, outlier corrupted data. Our method adopts a random sampling based hypothesis generation and works on the premise that inliers are densely packed around the structure, while the outliers are sparsely spread out. We leverage consensus maximization by defining the residual density, which is a simple and efficient measure of density in the 1-D residual space. We locate the inlier-outlier boundary by using preference based point correlations together with the disparity in residual density of inliers and outliers. Finally, we employ a simple strategy that uses preference based hypothesis correlation and residual density to identify one hypothesis representing each structure and their corresponding inliers. The strength of the proposed approach is evaluated empirically by comparing with state-of-the-art techniques over synthetic data and the AdelaideRMF dataset.
@inproceedings{tiwari2017robust,title={Robust Multi-Model Fitting using Density and Preference Analysis},author={Tiwari, Lokender and Anand, Saket and Mittal, Sushil},booktitle={Asian Conference on Computer Vision (<b>ACCV</b>)},pages={308--323},year={2017},organization={Springer},}
2016
Fast Hypothesis Filtering for Multi-Structure Geometric Model Fitting
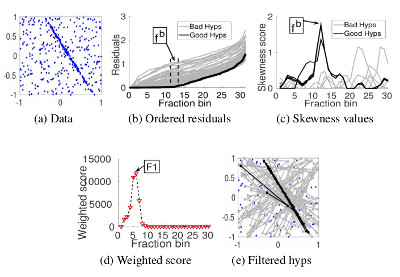
We propose a fast and efficient two-stage hypothesis filtering technique that can improve performance of clustering based robust multi-model fitting algorithms. Sampling based hypothesis generation is nondeterministic and permits little control over generating poor model hypotheses, often leading to a significant proportion of bad hypotheses. Our novel filtering approach leverages the asymmetry in the distributions of points around the inlier/outlier boundary via the sample skewness computed in the residual space. The output is a set of promising hypotheses which aid multi-model fitting algorithms in improving accuracy as well as running time. We validate our approach on the AdelaideRMF dataset and show favorable results along with comparisons to state-of-the-art.
@inproceedings{tiwari2016fast,title={Fast Hypothesis Filtering for Multi-Structure Geometric Model Fitting},author={Tiwari, Lokender and Anand, Saket},booktitle={IEEE International Conference on Image Processing (<b>ICIP</b>)},pages={3728--3732},year={2016},organization={IEEE},}
This disclosure relates generally to method and system for draping a 3D garment on a 3D human body. Dressing digital humans in 3D have gained much attention due to its use in online shopping and draping 3D garments over the 3D human body has immense applications in virtual try-on, animations, and accurate fitment of the 3D garment is the utmost importance. The proposed disclosure is a single unified garment deformation model that learns the shared space of variations for a body shape, a body pose, and a styling garment. The method receives a plurality of human body inputs to construct a 3D skinned garments for the subject. The deep draper network trained using a plurality of losses provides efficient deep neural network based method that predicts fast and accurate 3D garment images. The method couples the geometric and multi-view perceptual constraints that efficiently learn the garment deformation’s high-frequency geometry.
@misc{tiwari2022method,title={Method and System for Draping a 3D Garment on a 3D Human Body},author={Tiwari, Lokender and Bhowmick, Brojeshwar},year={2022},month=nov,publisher={Google Patents},note={US Patent App. 17/646,330},}
Pseudo RGB-D for Self-Improving Monocular Slam and Depth Prediction
Lokender Tiwari, Quoc-Huy Tran, Pan JI, and Manmohan Chandraker
A method for improving geometry-based monocular structure from motion (SfM) by exploiting depth maps predicted by convolutional neural networks (CNNs) is presented. The method includes capturing a sequence of RGB images from an unlabeled monocular video stream obtained by a monocular camera, feeding the RGB images into a depth estimation/refinement module, outputting depth maps, feeding the depth maps and the RGB images to a pose estimation/refinement module, the depths maps and the RGB images collectively defining pseudo RGB-D images, outputting camera poses and point clouds, and constructing a 3D map of a surrounding environment displayed on a visualization device.
@misc{tran2022pseudo,title={Pseudo RGB-D for Self-Improving Monocular Slam and Depth Prediction},author={Tiwari, Lokender and Tran, Quoc-Huy and JI, Pan and Chandraker, Manmohan},year={2022},month=oct,publisher={Google Patents},note={US Patent 11,468,585},}
State of the art approaches for 3D garment simulation approaches have the disadvantages that they 1) work on fixed garment type, 2) work on fixed body shapes, and 3) assume fixed garment topology. As a result, they do not offer a generic solution for garment simulation. Method and system disclosed herein use a combination of a body motion aware ARAP garment deformation and a Physics Enforcing Network (PEN), so as to generate garment simulations irrespective of garment type, body shapes, and garment topology, thus offering a generic solution.
Method and System for Estimating Temporally Consistent 3D Human Shape and Motion from Monocular Video
Estimating temporally consistent 3D human body shape, pose, and motion from a monocular video is a challenging task due to occlusions, poor lightning conditions, complex articulated body poses, depth ambiguity, and limited availability of annotated data. Embodiments of present disclosure provide a method for temporally consistent motion estimation from monocular video. A monocular video of person(s) is captured by a weak perspective camera and spatial features of body of the persons are extracted from each frame of the video. Then, initial estimates of body shape, body pose, and features of the weak perspective camera are obtained. The spatial features and initial estimates are then aggregated to obtain spatio-temporal features by a combination of self-similarity matrices between the spatial features, pose and the camera and self-attention maps of the camera features and the spatial features. The spatio-temporal aggregated features are then used to predict shape and pose parameters of the person(s).
Systems and Methods for Simulating Garments on Target Body Poses
Garments in their natural form are represented by meshes, where vertices (entities) are connected (related) to each other through mesh edges. Earlier methods largely ignored this relational nature of garment data while modeling garments and networks. Present disclosure provides a particle-based garment system and method that learn to simulate template garments on the target arbitrary body poses by representing physical state of garment vertices as particles, expressed as nodes in a graph, and dynamics (velocities of garment vertices) is computed through a learned message-passing. The system and method exploit this relational nature of garment data and network implemented to enforce strong relational inductive bias in garment dynamics thereby accurately simulating garments on the target body pose conditioned on body motion and fabric type at any resolution without modification even for loose garments, unlike existing state-of-the-art (SOTA) methods.